Utilizing the Earth Mover's Distance for Similarity Searches
Similarity-based search of Web services is a challenging issue associated with service-oriented computing and cloud computing. Consider in the case of a composite service where one component service that makes up the composite service fails, one needs to search and find the best replacement service. Moreover, similarity search is also a crucial task in many other practical applications, such as data mining within cluster applications.
The Vector Space Model
Most search engines compute the similarity distance between two web documents based on the Vector Space Model (VSM), which results in the incompleteness of search results. This is because VSM computes a similarity score by only matching the keywords at the same positions in both the query and the document vectors, not considering the impact of the keywords at neighboring positions.
In addition, a singleton keyword is insufficient for specifying needs of a web search consumer. However, a long list of keywords is likely to lead to many irrelevance search results with exact keyword matching. Clearly, a better approach for similarity-based search is needed.
Consider EMD
To overcome the limitations mentioned about the VSM consider an EMD-based similarity search algorithm for finding similar web results based on the partial match of any of the web results attributes or a combination of them.
EMD has been widely employed in multimedia databases to better approximate human visual perception, speech recognition, and document retrieval because EMD can effectively capture the differences between the distributions of two objects’ main features, and allow for partial matching.
This means if keywords in a query only match partially the keywords in a service record, EMD-based similarity search is still able to find the most similar matching pairs of words. To overcome the limitation of EMD-based computation complexity, consider using filtering techniques to minimize the total number of actual EMD computations.
EMD-based Similarity Search
The cornerstone of this similarity search is to employ an EMD-based search algorithm to locate similar and hopefully relevant results. To take advantage of finding similar and partial matches in web searches use EMD as a distance measure between query q and record r which describes their similarity:
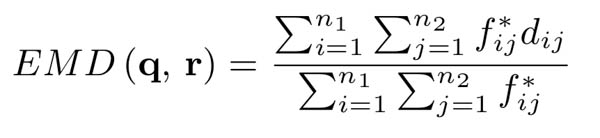
Where f* is the optimal flow that involves computing the optimal solutions by using the following linear program LP with variable fij :
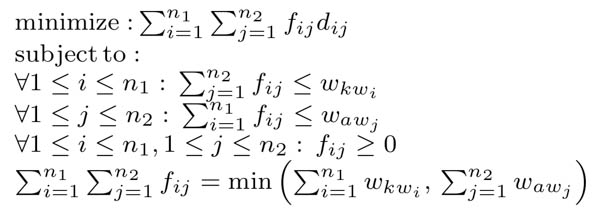
Conclusion
EMD is a perfectly acceptable algorithm for similarity between searches and records. However, its big drawback is relevance. For example, the EMD score between the words cat and car is 1. The words are very similar, but they are not very relevant. If I was performing a search for cars, I would very likely get several results for cats because the words themselves are very similar.
To overcome this limitation one would have to consider using pre-filters to establish relevance to the initial query. EMD isn't ready for primetime and it would never be considered seriously for the primary algorithm for web searches, but in conjunction with other popular and established web search algorithms (such as VSM), EMD can provide a utility to help improve results by pulling in records that may have been glanced over. One main area EMD excels at is finding similar (and possibly relevant) records that have misspellings which other algorithms would otherwise miss.
